Firecrawl MCP connector
Bearer TokenAIDeveloper ToolsSearchConnect to Firecrawl MCP. Scrape, crawl, search, extract structured data, and monitor websites using Firecrawl's AI-powered web scraping API.
Firecrawl MCP connector
-
Install the SDK
Section titled “Install the SDK”Terminal window npm install @scalekit-sdk/nodeTerminal window pip install scalekit -
Set your credentials
Section titled “Set your credentials”Add your Scalekit credentials to your
.envfile. Find values in app.scalekit.com > Developers > API Credentials..env SCALEKIT_ENVIRONMENT_URL=<your-environment-url>SCALEKIT_CLIENT_ID=<your-client-id>SCALEKIT_CLIENT_SECRET=<your-client-secret> -
Set up the connector
Section titled “Set up the connector”Register your Firecrawl MCP credentials with Scalekit so it can authenticate requests on your behalf. You do this once per environment.
Dashboard setup steps
Register your Firecrawl API key with Scalekit so it can authenticate and proxy scraping requests on behalf of your users. Firecrawl MCP uses API key authentication — there is no redirect URI or OAuth flow.
-
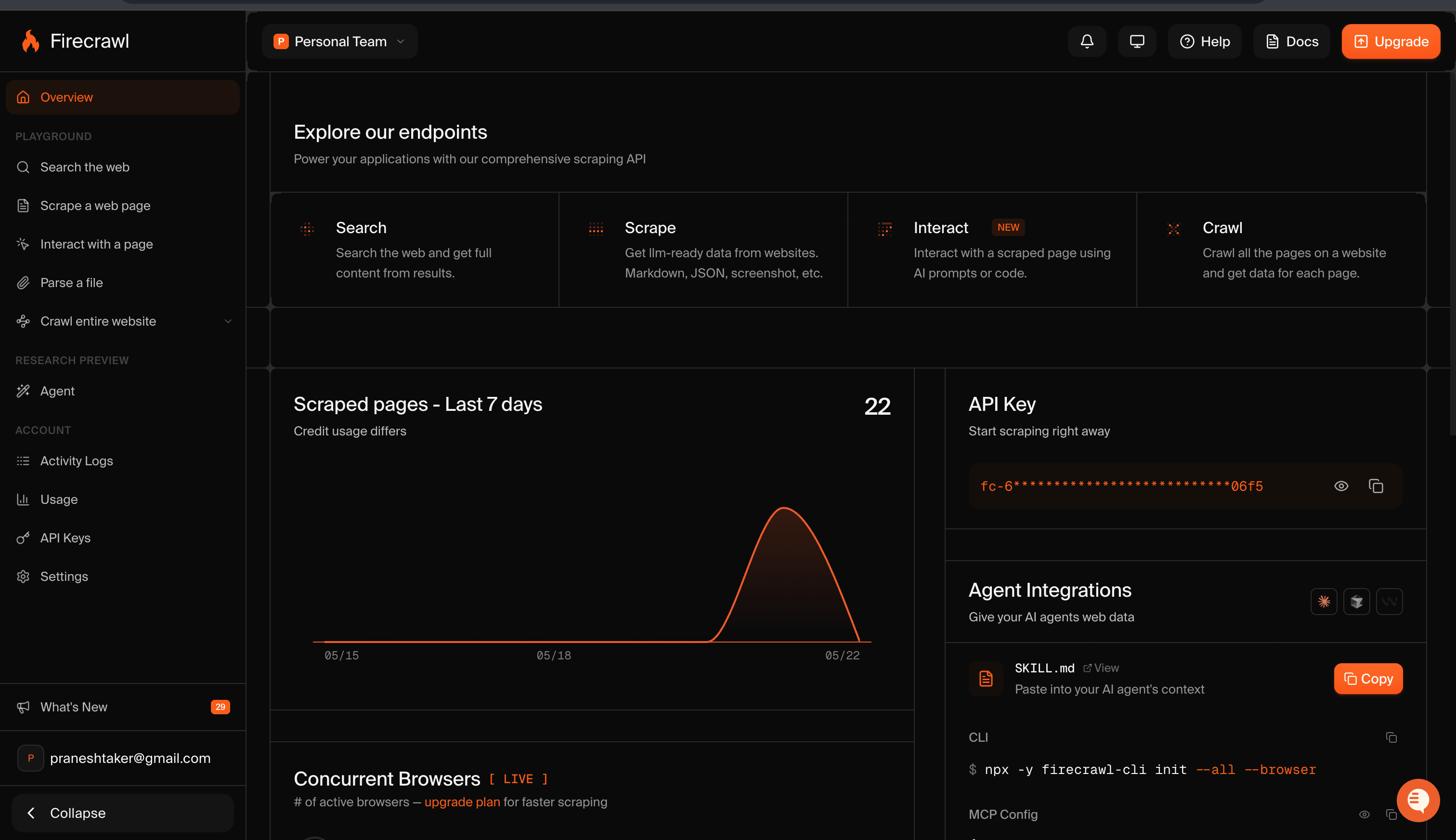
Get a Firecrawl API key
- Go to firecrawl.dev and sign in or create a free account.
- Your API key is shown on the Overview page under API Key. Copy it — it starts with
fc-.
-
Create a connection in Scalekit
- In the Scalekit dashboard, go to AgentKit → Connections → Create Connection.
- Search for Firecrawl MCP and click Create.
- Note the Connection name — use this as
connection_namein your code (e.g.,firecrawlmcp).
-
Add a connected account
Connected accounts link a specific user identifier in your system to a Firecrawl API key. Add them via the dashboard for testing, or via the Scalekit API in production.
Via dashboard (for testing)
- Open the connection and click the Connected Accounts tab → Add account.
- Fill in Your User’s ID and API Key, then click Save.
Via API (for production)
await scalekit.actions.upsertConnectedAccount({connectionName: 'firecrawlmcp',identifier: 'user_123',credentials: { token: 'fc-...' },});scalekit_client.actions.upsert_connected_account(connection_name="firecrawlmcp",identifier="user_123",credentials={"token": "fc-..."})
-
-
Make your first call
Section titled “Make your first call”quickstart.ts import { ScalekitClient } from '@scalekit-sdk/node'import 'dotenv/config'const scalekit = new ScalekitClient(process.env.SCALEKIT_ENV_URL,process.env.SCALEKIT_CLIENT_ID,process.env.SCALEKIT_CLIENT_SECRET,)const actions = scalekit.actionsconst connector = 'firecrawlmcp'const identifier = 'user_123'// Make your first callconst result = await actions.executeTool({connector,identifier,toolName: 'firecrawlmcp_firecrawl_browser_list',toolInput: {},})console.log(result)quickstart.py import osfrom scalekit.client import ScalekitClientfrom dotenv import load_dotenvload_dotenv()scalekit_client = ScalekitClient(env_url=os.getenv("SCALEKIT_ENV_URL"),client_id=os.getenv("SCALEKIT_CLIENT_ID"),client_secret=os.getenv("SCALEKIT_CLIENT_SECRET"),)actions = scalekit_client.actionsconnection_name = "firecrawlmcp"identifier = "user_123"# Make your first callresult = actions.execute_tool(tool_input={},tool_name="firecrawlmcp_firecrawl_browser_list",connection_name=connection_name,identifier=identifier,)print(result)
What you can do
Section titled “What you can do”Connect this agent connector to let your agent:
- Search firecrawl — Send structured feedback on a previous search result to help improve future results
- Scrape firecrawl — Scrape a single URL and return its content in one or more formats (markdown, JSON, screenshot, etc.)
- Update firecrawl monitor — Update monitor settings such as name, status, schedule, or scrape options
- Run firecrawl monitor — Trigger an immediate check for a monitor outside its normal schedule
- List firecrawl monitor, firecrawl browser — List all monitors configured for the authenticated account, with pagination
- Get firecrawl monitor — Retrieve the configuration and status of a single monitor by its ID
Common workflows
Section titled “Common workflows”Scrape a page
Use firecrawlmcp_firecrawl_scrape to extract clean markdown content from any URL.
const result = await actions.executeTool({ connectionName: 'firecrawlmcp', identifier: 'user_123', toolName: 'firecrawlmcp_firecrawl_scrape', toolInput: { url: 'https://docs.example.com/getting-started', onlyMainContent: true, },});console.log(result.data);result = actions.execute_tool( connection_name="firecrawlmcp", identifier="user_123", tool_name="firecrawlmcp_firecrawl_scrape", tool_input={ "url": "https://docs.example.com/getting-started", "onlyMainContent": True, },)print(result.data)Search the web
Use firecrawlmcp_firecrawl_search to run a live web search and get scraped content from the top results.
const result = await actions.executeTool({ connectionName: 'firecrawlmcp', identifier: 'user_123', toolName: 'firecrawlmcp_firecrawl_search', toolInput: { query: 'best practices for API rate limiting 2026', limit: 5, },});console.log(result.data);result = actions.execute_tool( connection_name="firecrawlmcp", identifier="user_123", tool_name="firecrawlmcp_firecrawl_search", tool_input={ "query": "best practices for API rate limiting 2026", "limit": 5, },)print(result.data)Extract structured data from a URL
Use firecrawlmcp_firecrawl_extract with a natural-language prompt and optional JSON Schema to pull structured data from one or more pages.
const result = await actions.executeTool({ connectionName: 'firecrawlmcp', identifier: 'user_123', toolName: 'firecrawlmcp_firecrawl_extract', toolInput: { urls: ['https://example.com/pricing'], prompt: 'Extract all pricing plan names and their monthly costs.', },});console.log(result.data);result = actions.execute_tool( connection_name="firecrawlmcp", identifier="user_123", tool_name="firecrawlmcp_firecrawl_extract", tool_input={ "urls": ["https://example.com/pricing"], "prompt": "Extract all pricing plan names and their monthly costs.", },)print(result.data)Tool list
Section titled “Tool list”Use the exact tool names from the Tool list below when you call execute_tool. If you’re not sure which name to use, list the tools available for the current user first.
firecrawlmcp_firecrawl_agent#Start an autonomous AI research agent that browses the web to answer a prompt. Returns a job ID; poll with firecrawlmcp_firecrawl_agent_status for results.3 params
Start an autonomous AI research agent that browses the web to answer a prompt. Returns a job ID; poll with firecrawlmcp_firecrawl_agent_status for results.
promptstringrequiredNatural-language instruction to guide extraction or crawling.schemaobjectoptionalJSON Schema defining the structure of data to extract.urlsarrayoptionalList of URLs to extract structured data from.firecrawlmcp_firecrawl_agent_status#Retrieve the status and results of a running AI research agent job by its ID.1 param
Retrieve the status and results of a running AI research agent job by its ID.
idstringrequiredThe unique identifier of the resource.firecrawlmcp_firecrawl_browser_create#Create a persistent browser session for interactive scraping.4 params
Create a persistent browser session for interactive scraping.
activityTtlnumberoptionalSeconds of inactivity after which the session is automatically destroyed.profileobjectoptionalNamed browser profile to use for authenticated scraping.streamWebViewbooleanoptionalSet to true to stream the browser viewport during the session.ttlnumberoptionalSession lifetime in seconds after creation.firecrawlmcp_firecrawl_browser_delete#Destroy a browser session and release its resources.1 param
Destroy a browser session and release its resources.
sessionIdstringrequiredThe ID of the browser session. Get it from firecrawlmcp_firecrawl_browser_create.firecrawlmcp_firecrawl_browser_list#List active or destroyed browser sessions for the account.1 param
List active or destroyed browser sessions for the account.
statusstringoptionalFilter browser sessions by status. Accepted values: active, destroyed.firecrawlmcp_firecrawl_check_crawl_status#Check the progress and results of an in-progress crawl job by its ID.1 param
Check the progress and results of an in-progress crawl job by its ID.
idstringrequiredThe unique identifier of the resource.firecrawlmcp_firecrawl_crawl#Start a crawl job that extracts content from all pages of a website. Returns a job ID; use firecrawlmcp_firecrawl_check_crawl_status to poll for results.15 params
Start a crawl job that extracts content from all pages of a website. Returns a job ID; use firecrawlmcp_firecrawl_check_crawl_status to poll for results.
urlstringrequiredThe URL of the page or website to scrape, crawl, or map.allowExternalLinksbooleanoptionalSet to true to follow links to external domains.allowSubdomainsbooleanoptionalSet to true to crawl subdomains of the target domain.crawlEntireDomainbooleanoptionalSet to true to crawl all paths on the domain, not just the starting URL subtree.deduplicateSimilarURLsbooleanoptionalSet to true to skip URLs that are similar to already-crawled URLs.delaynumberoptionalMilliseconds to wait between requests to avoid rate limiting.excludePathsarrayoptionalURL path patterns to exclude from the crawl (e.g. ["/admin", "/login"]).ignoreQueryParametersbooleanoptionalSet to true to treat URLs differing only by query string as duplicates.includePathsarrayoptionalURL path patterns to restrict the crawl to (e.g. ["/blog/*"]).limitnumberoptionalMaximum number of results to return.maxConcurrencynumberoptionalMaximum number of concurrent requests during a crawl.maxDiscoveryDepthnumberoptionalMaximum link depth to follow from the starting URL.promptstringoptionalNatural-language instruction to guide extraction or crawling.scrapeOptionsobjectoptionalScraping options applied to each page during crawl or search (formats, tags, etc.).sitemapstringoptionalHow to use the sitemap: include to discover URLs from it, only to crawl only sitemap URLs, skip to ignore it.firecrawlmcp_firecrawl_extract#Extract structured data from one or more URLs using a natural-language prompt and optional JSON Schema.6 params
Extract structured data from one or more URLs using a natural-language prompt and optional JSON Schema.
urlsarrayrequiredList of URLs to extract structured data from.allowExternalLinksbooleanoptionalSet to true to follow links to external domains.enableWebSearchbooleanoptionalSet to true to supplement extraction with live web search results.includeSubdomainsbooleanoptionalSet to true to include subdomains of the target domain.promptstringoptionalNatural-language instruction to guide extraction or crawling.schemaobjectoptionalJSON Schema defining the structure of data to extract.firecrawlmcp_firecrawl_interact#Run code or a natural-language prompt in a live browser session for a previously scraped page.5 params
Run code or a natural-language prompt in a live browser session for a previously scraped page.
scrapeIdstringrequiredThe ID of the active scrape session. Get it from firecrawlmcp_firecrawl_scrape when using interact.codestringoptionalCode snippet to execute in the browser session.languagestringoptionalProgramming language for the code snippet to execute in the browser session.promptstringoptionalNatural-language instruction to guide extraction or crawling.timeoutnumberoptionalMilliseconds to wait for the browser interaction to complete.firecrawlmcp_firecrawl_interact_stop#End an active browser interaction session and release its resources.1 param
End an active browser interaction session and release its resources.
scrapeIdstringrequiredThe ID of the active scrape session. Get it from firecrawlmcp_firecrawl_scrape when using interact.firecrawlmcp_firecrawl_map#Discover all indexed URLs on a website or within a URL subtree, with optional search filtering.6 params
Discover all indexed URLs on a website or within a URL subtree, with optional search filtering.
urlstringrequiredThe URL of the page or website to scrape, crawl, or map.ignoreQueryParametersbooleanoptionalSet to true to treat URLs differing only by query string as duplicates.includeSubdomainsbooleanoptionalSet to true to include subdomains of the target domain.limitnumberoptionalMaximum number of results to return.searchstringoptionalSearch term to filter URLs returned by the map.sitemapstringoptionalHow to use the sitemap: include to discover URLs from it, only to crawl only sitemap URLs, skip to ignore it.firecrawlmcp_firecrawl_monitor_check#Retrieve the page-level diff results for a single monitor check run.5 params
Retrieve the page-level diff results for a single monitor check run.
checkIdstringrequiredThe ID of a specific monitor check. Get it from firecrawlmcp_firecrawl_monitor_checks.idstringrequiredThe unique identifier of the resource.limitintegeroptionalMaximum number of results to return.pageStatusstringoptionalFilter check results to pages with this change status.skipintegeroptionalNumber of items to skip for pagination.firecrawlmcp_firecrawl_monitor_checks#List the historical check runs for a monitor, with pagination.3 params
List the historical check runs for a monitor, with pagination.
idstringrequiredThe unique identifier of the resource.limitintegeroptionalMaximum number of results to return.offsetintegeroptionalNumber of items to skip for pagination.firecrawlmcp_firecrawl_monitor_create#Create a recurring Firecrawl monitor that scrapes a URL on a schedule and diffs results against the previous run.1 param
Create a recurring Firecrawl monitor that scrapes a URL on a schedule and diffs results against the previous run.
bodyobjectrequiredMonitor configuration object. Include name, url, schedule (cron), and scrapeOptions.firecrawlmcp_firecrawl_monitor_delete#Permanently delete a monitor and stop its scheduled checks.1 param
Permanently delete a monitor and stop its scheduled checks.
idstringrequiredThe unique identifier of the resource.firecrawlmcp_firecrawl_monitor_get#Retrieve the configuration and status of a single monitor by its ID.1 param
Retrieve the configuration and status of a single monitor by its ID.
idstringrequiredThe unique identifier of the resource.firecrawlmcp_firecrawl_monitor_list#List all monitors configured for the authenticated account, with pagination.2 params
List all monitors configured for the authenticated account, with pagination.
limitintegeroptionalMaximum number of results to return.offsetintegeroptionalNumber of items to skip for pagination.firecrawlmcp_firecrawl_monitor_run#Trigger an immediate check for a monitor outside its normal schedule.1 param
Trigger an immediate check for a monitor outside its normal schedule.
idstringrequiredThe unique identifier of the resource.firecrawlmcp_firecrawl_monitor_update#Update monitor settings such as name, status, schedule, or scrape options.2 params
Update monitor settings such as name, status, schedule, or scrape options.
bodyobjectrequiredMonitor configuration object. Include name, url, schedule (cron), and scrapeOptions.idstringrequiredThe unique identifier of the resource.firecrawlmcp_firecrawl_scrape#Scrape a single URL and return its content in one or more formats (markdown, JSON, screenshot, etc.).21 params
Scrape a single URL and return its content in one or more formats (markdown, JSON, screenshot, etc.).
urlstringrequiredThe URL of the page or website to scrape, crawl, or map.excludeTagsarrayoptionalHTML tags or CSS selectors to remove from extracted content.formatsarrayoptionalOutput formats to return. Accepted values: markdown, html, rawHtml, screenshot, links, summary, branding, json, query, audio.includeTagsarrayoptionalHTML tags or CSS selectors to restrict extraction to.jsonOptionsobjectoptionalOptions for JSON extraction: prompt and optional JSON Schema.locationobjectoptionalGeographic location for localized content. Pass an object with country (ISO 3166-1 alpha-2 code) and optional languages array.lockdownbooleanoptionalSet to true to serve from cache only, without any outbound network requests.maxAgenumberoptionalMaximum cache age in seconds; serve cached data up to this age for faster responses.mobilebooleanoptionalSet to true to emulate a mobile browser viewport.onlyMainContentbooleanoptionalSet to true to strip navigation, headers, footers, and other boilerplate.parsersarrayoptionalAdditional parsers to apply. Accepted values: pdf.pdfOptionsobjectoptionalOptions for PDF parsing, such as the maximum number of pages.profileobjectoptionalNamed browser profile to use for authenticated scraping.proxystringoptionalProxy tier to use: basic for standard, stealth or enhanced for bot-resistant sites.queryOptionsobjectoptionalOptions for query-mode extraction: the prompt and response mode.removeBase64ImagesbooleanoptionalSet to true to strip inline base64-encoded images from the output.screenshotOptionsobjectoptionalOptions for screenshot capture, such as full-page and quality settings.skipTlsVerificationbooleanoptionalSet to true to skip TLS certificate validation (use for self-signed certs).storeInCachebooleanoptionalSet to true to cache this response for future maxAge-based lookups.waitFornumberoptionalMilliseconds to wait for JavaScript to render before extracting content.zeroDataRetentionbooleanoptionalSet to true to prevent Firecrawl from storing any data for this request.firecrawlmcp_firecrawl_search#Search the web and optionally scrape content from the top results.10 params
Search the web and optionally scrape content from the top results.
querystringrequiredThe search query to send to Firecrawl web search.enterprisearrayoptionalSearch mode tier. Accepted values: default, anon, zdr.excludeDomainsarrayoptionalDomains to exclude from search results.filterstringoptionalAdvanced search filter string in Google tbs format.includeDomainsarrayoptionalRestrict search results to these domains only.limitnumberoptionalMaximum number of results to return.locationstringoptionalGeographic location for localized scraping or search results.scrapeOptionsobjectoptionalScraping options applied to each page during crawl or search (formats, tags, etc.).sourcesarrayoptionalSources to include. Each item must have a type field. Accepted values for type: web, images, news.tbsstringoptionalTime-based search filter (e.g. qdr:d for past day, qdr:w for past week).firecrawlmcp_firecrawl_search_feedback#Send structured feedback on a previous search result to help improve future results.5 params
Send structured feedback on a previous search result to help improve future results.
ratingstringrequiredYour overall quality rating for the search result.searchIdstringrequiredThe ID of a previous search result. Returned by firecrawlmcp_firecrawl_search.missingContentarrayoptionalContent types or topics that were missing from the search results.querySuggestionsstringoptionalAlternative search queries that might yield better results.valuableSourcesarrayoptionalURLs you found particularly useful in the search results.